在现代数据中心里,IT架构早已不是简单的"服务器+网络"组合。从底层的计算、存储、网络设备,到上层的操作系统、中间件、数据库,再到前端业务系统——每一环都紧密耦合、相互依赖。一旦某个节点出现异常,往往会像多米诺骨牌一样,引发一连串连锁告警。
传统监控平台的问题恰恰在这里:当业务突然变慢或中断,运维人员打开告警列表,看到的不是"一个故障",而是十几条甚至上百条零散告警——服务器宕机、数据库连接失败、中间件线程阻塞、应用响应超时、网络丢包……到底哪个是根源?哪个只是"受害者"?排查如同大海捞针,业务恢复遥遥无期。
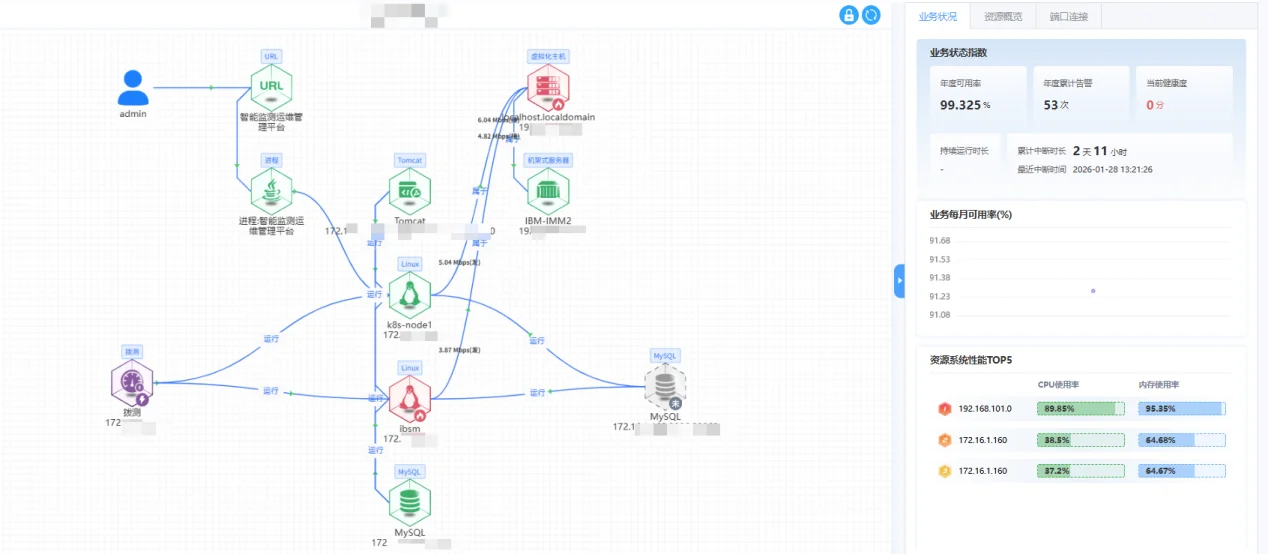
一、看得清:全栈资源自动关联,构建"业务-IT"映射图谱
云新信息(CloudSino)的智能监测运维管理平台通过带内+带外融合采集,自动发现并关联以下层级:
- 硬件层:X86/ARM服务器、存储阵列、光纤交换机、UPS、精密空调等;
- 系统层:Linux、Windows、麒麟、统信UOS等操作系统;
- 中间件与数据库:Tomcat、WebLogic、Oracle、达梦、MongoDB等;
- 应用与业务:挂号系统、ERP、OA、官网、APP后端等。
更重要的是,平台能自动构建业务拓扑,清晰展示"某业务系统依赖哪些数据库,运行在哪几台虚拟机上,底层又由哪台物理服务器和存储支撑"。当故障发生,不再是看一堆IP和指标,而是直接定位到受影响的业务链路。
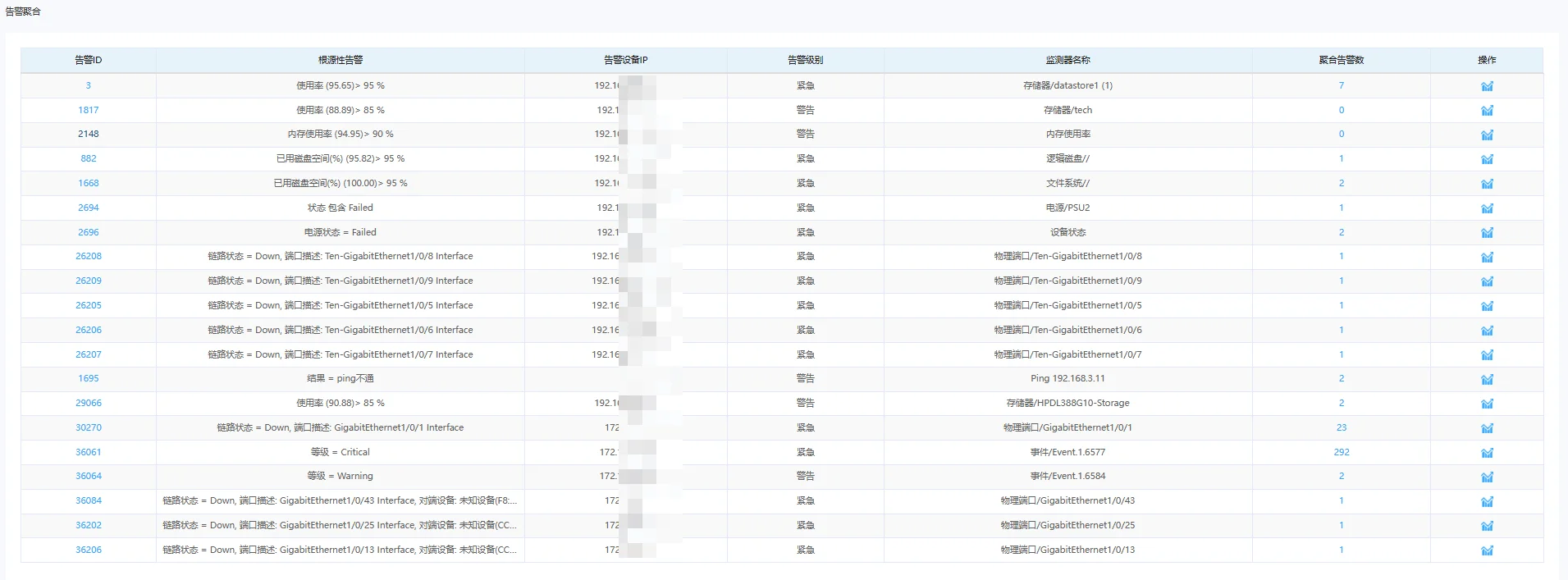
二、判得准:告警聚合 + 根因分析,从"噪音"中提取信号
面对海量告警,我们具备三大核心能力:
- 告警智能聚合:自动识别由同一故障引发的多条告警,将它们聚合成一个事件卡片,避免信息过载。
- 根因自动定位:基于资源依赖关系与历史故障模式,AI可判断出最可能的故障源头。例如:当同时出现"应用超时""数据库连接失败""服务器心跳丢失",系统会高亮提示:"根因告警:物理服务器宕机(IP: 192.168.10.55)"。
- 故障影响预判:结合业务拓扑,平台还能预估本次故障会影响哪些部门、哪些用户,帮助运维团队优先处理高价值业务。
三、处得快:闭环处置 + 自动恢复,让故障"自愈"
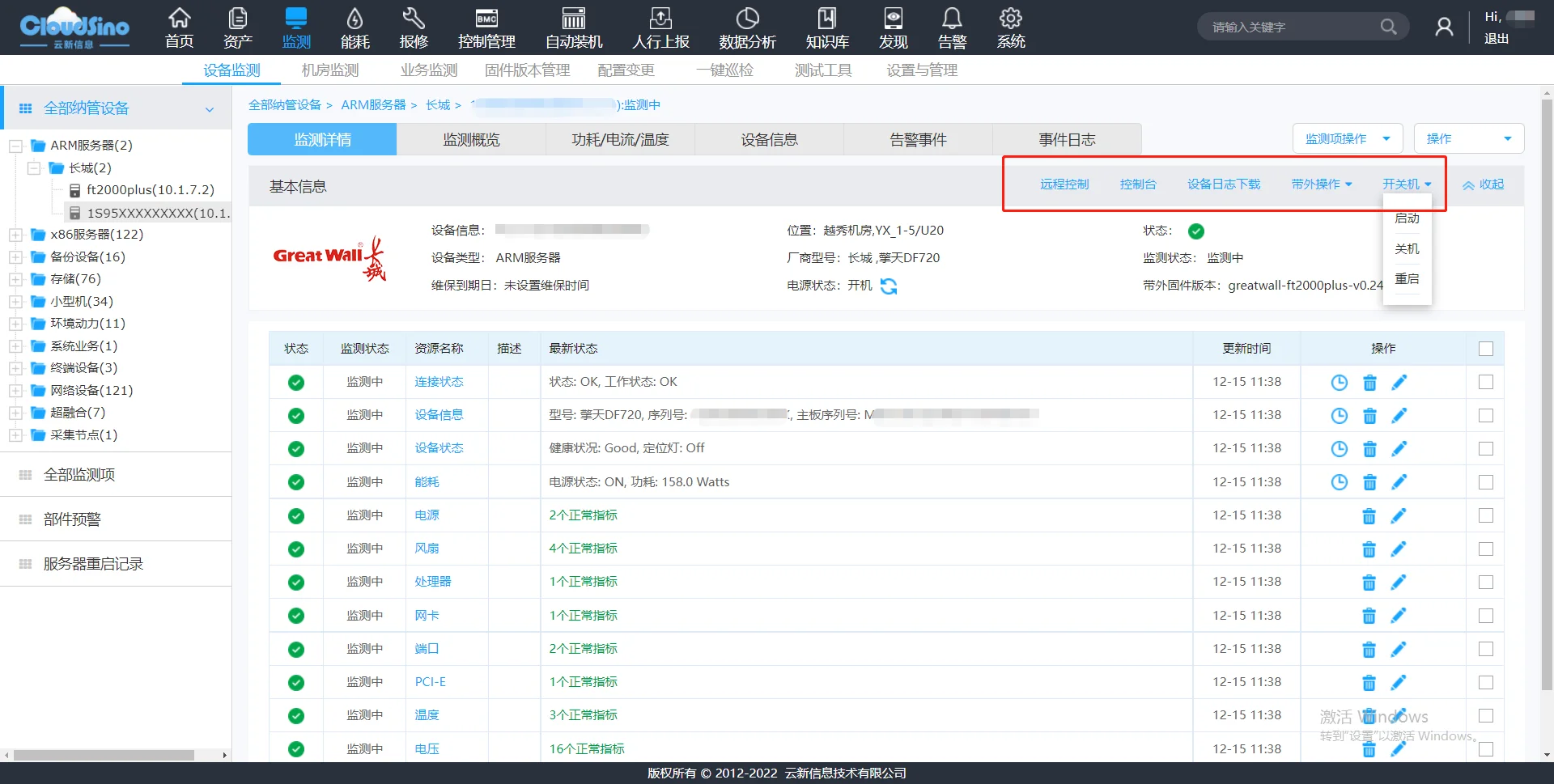
发现问题只是第一步,快速恢复才是关键。CloudSino平台支持:
- 自动转工单:根因告警触发ITSM流程,自动分配责任人;
- 远程一键操作:通过vKVM远程重启服务器、重载服务;
- 脚本自动执行:针对已知故障场景,可配置自动化修复脚本,实现"检测→诊断→修复→验证"闭环。
结语:从"救火队员"到"业务守护者"
在AI与数字化加速渗透的今天,数据中心的复杂度只会越来越高。靠人力盯屏、靠经验猜错,已无法应对现代IT系统的瞬息万变。云新信息以13年带外管理技术沉淀、400万+设备纳管经验、14大全国技术支持中心,打造了一套真正面向业务连续性的智能运维体系——不止于监控,更在于理解;不止于告警,更在于决策。