3月9日,腾讯云推出的"全场景职场AI智能体"WorkBuddy正式开启公测。上线仅数小时,因用户访问量远超预期,核心服务一度出现登录失败、响应延迟等状况。虽然技术团队迅速进行了10倍扩容并恢复了稳定,但这次"幸福的烦恼"给所有正在建设或运营智算中心的企业敲响了警钟:当AI应用瞬间爆发时,你的算力底座真的准备好了吗?
WorkBuddy的短暂中断,表面看是流量洪峰,实则暴露了一个深层的行业隐忧:我们对AI算力的真实消耗与分布,往往处于"雾里看花"的状态。GPU闲置率超40%却无人知晓?训练任务因局部过热降频导致效率骤降?这些"算力黑洞",正在无声吞噬你的AI投资回报。
一、算力不清,何谈调度?从"盲人摸象"到"全局可视"
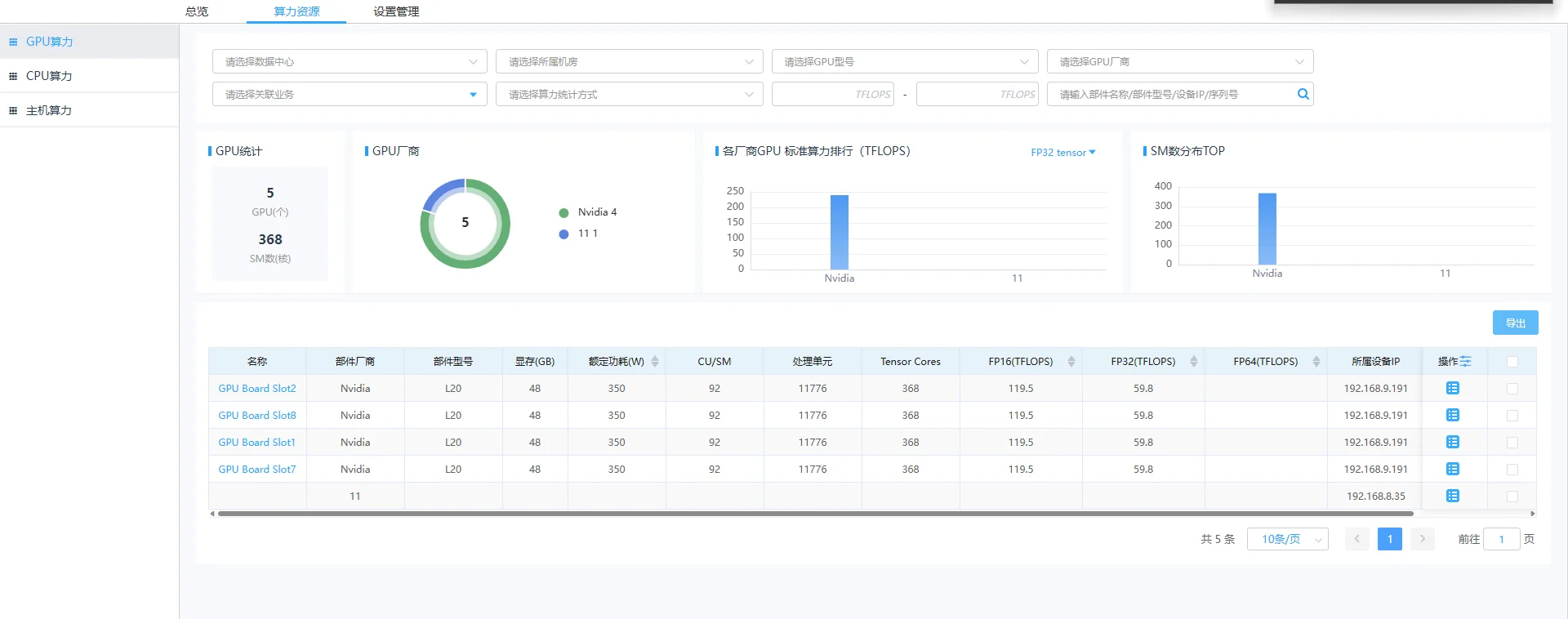
面对智算中心复杂的异构资源,我们需要一套能"看得全、联得通"的综合运维管理平台。CloudSino智算中心综合运维管理平台的核心在于打破数据孤岛:
- U位级资产自动发现:每一块GPU、每一台服务器,精准定位到机柜U位;
- "带内+带外"双通道采集:无需在操作系统安装Agent,通过IPMI、Redfish、SNMP、SSH等协议统一纳管;
- GPU资源深度监测:同时采集带外状态(健康度、资产信息)与带内性能(显存使用、算力利用率)。
二、算力浪费,藏在"孤岛"之中:打通IT与动环
- 全域数据关联:将温湿度、PDU、UPS、空调等动环数据与IT设备指标统一关联分析;
- 能耗画像构建:自动采集服务器进风口温度与实时功耗,构建设备级热量图与能耗画像;
- 全链路下钻:支持"应用-网络-环境"全链路根因分析。
三、从"被动救火"到"主动治理":构建算力数字孪生底座
- 裸金属自动部署:从验收到OS安装、压力测试,一键交付标准化AI服务器;
- 自定义脚本监测:灵活定义Shell/JDBC/SNMP监测项;
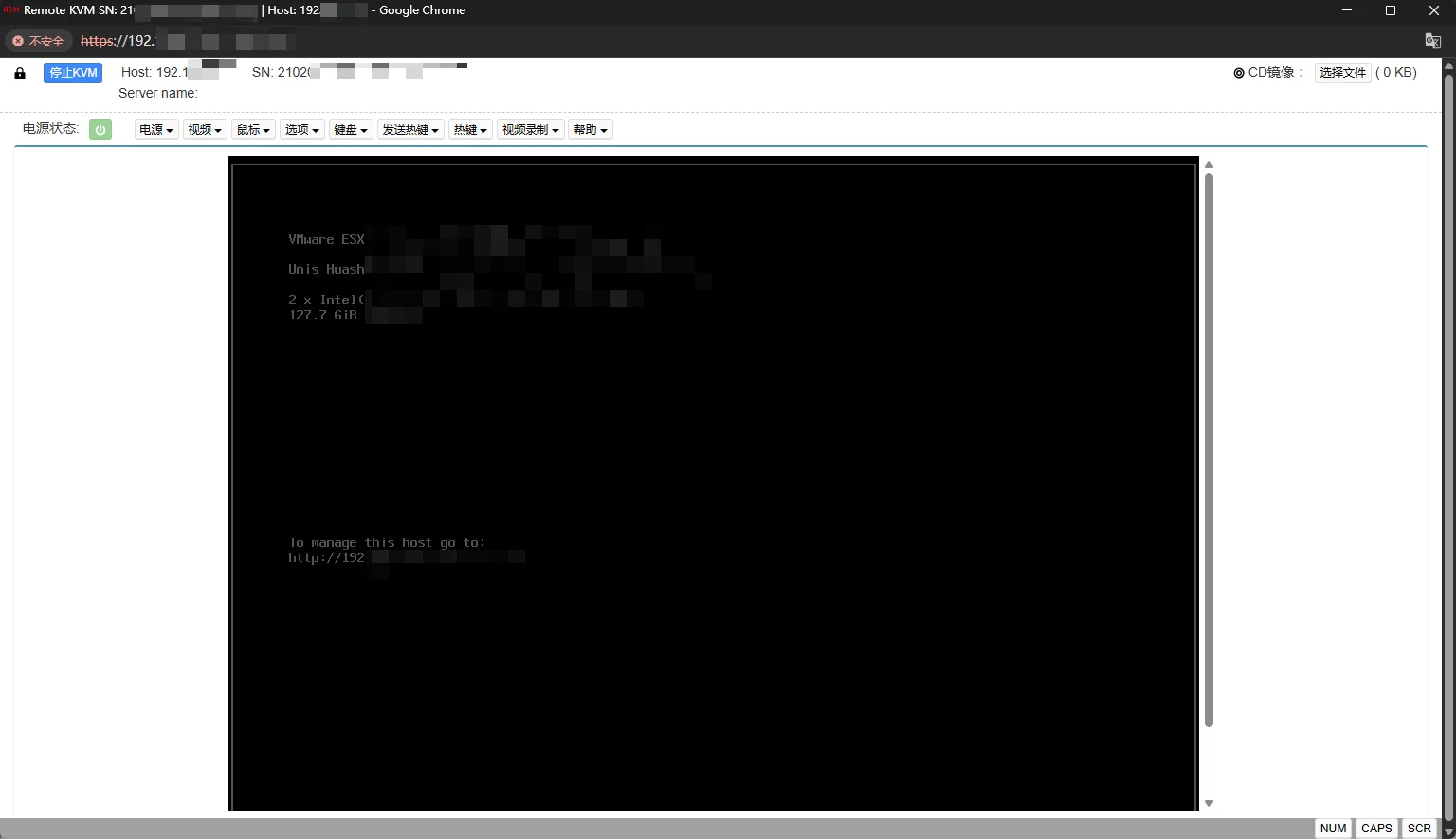
- 远程KVM控制:即使操作系统崩溃,仍可通过带外管理口远程修复。
结语:真正的AI竞争力,始于"算得清",成于"管得精"
WorkBuddy的一次小插曲,敲响了所有AI企业的警钟:算力不是买了就等于有了,更不等于能用好。CloudSino智算中心综合运维管理平台,融合全栈监控、物理位置、能耗动环与自动化控制,致力于为企业构建一个"看得全、联得通、判得准、控得住"的智能算力治理底座。